API Documentation¶
Getting Started¶
To parse text to UCCA passages, download a model file from the latest release, extract it, and use the following code template:
from tupa.parse import Parser
from ucca.convert import from_text
parser = Parser("models/ucca_bilstm")
for passage in parser.parse(from_text(...))):
...
Each passage instantiates the ucca.core.Passage class.
tupa.parse Module¶
Functions¶
average_f1(scores[, eval_type]) |
|
filter_passages_for_bert(passages, args) |
|
from_text_format(*args, **kwargs) |
|
generate_and_len(it) |
|
get_eval_type(scores) |
|
get_output_converter(out_format[, default]) |
|
glob(pathname, *[, recursive]) |
Return a list of paths matching a pathname pattern. |
main() |
|
main_generator() |
|
percents_str(part, total[, infix, fraction]) |
|
print_scores(scores, filename[, prefix, …]) |
|
read_passages(args, files) |
|
set_traceback_listener([sig]) |
|
single_to_iter(it) |
|
to_lower_case(passages) |
|
train_test(train_passages, dev_passages, …) |
Train and test parser on given passage :param train_passages: passage to train on :param dev_passages: passages to evaluate on every iteration :param test_passages: passages to test on after training :param args: extra argument :param model_suffix: string to append to model filename before file extension :return: generator of Scores objects: dev scores for each training iteration (if given dev), and finally test scores |
Classes¶
AbstractParser(config, models[, training, …]) |
|
BatchParser(*args, **kwargs) |
Parser for a single training iteration or single pass over dev/test passages |
ClassifierProperty |
An enumeration. |
Enum |
Generic enumeration. |
Iterations(args) |
|
Model(filename[, config]) |
|
Oracle(passage) |
Oracle to produce gold transition parses given UCCA passages To be used for creating training data for a transition-based UCCA parser :param passage gold passage to get the correct edges from |
ParseMode |
An enumeration. |
Parser([model_files, config, beam]) |
Main class to implement transition-based UCCA parser |
ParserException |
|
PassageParser(passage, *args, **kwargs) |
Parser for a single passage, has a state and optionally an oracle |
State(passage) |
The parser’s state, responsible for applying actions and creating the final Passage :param passage: a Passage object to get the tokens from, and everything else if training |
defaultdict |
defaultdict(default_factory[, …]) –> dict with default factory |
partial |
partial(func, *args, **keywords) - new function with partial application of the given arguments and keywords. |
Class Inheritance Diagram¶
tupa.config Module¶
Functions¶
add_param_arguments([ap, arg_default]) |
|
deepcopy(x[, memo, _nil]) |
Deep copy operation on arbitrary Python objects. |
load_enum(filename) |
Classes¶
CategoricalParameter(values, string) |
|
Hyperparams(parent[, shared]) |
|
HyperparamsInitializer([name]) |
|
Iterations(args) |
Class Inheritance Diagram¶

tupa.model Module¶
Functions¶
load_json(filename) |
Load dictionary from JSON file :param filename: file to read from |
remove_backup(*filenames) |
|
save_json(filename, d) |
Save dictionary to JSON file :param filename: file to write to :param d: dictionary to save |
Classes¶
Actions([actions, size]) |
|
AutoIncrementDict([size, keys, d, unknown]) |
DefaultOrderedDict that returns an auto-incrementing index for new keys |
Classifier(config, labels[, input_params]) |
Interface for classifier used by the parser. |
ClassifierProperty |
An enumeration. |
Enum |
Generic enumeration. |
FeatureParameters(suffix, dim, size[, …]) |
|
Model(filename[, config]) |
|
OrderedDict |
Dictionary that remembers insertion order |
ParameterDefinition(args, name, attr_to_arg) |
|
UnknownDict([d]) |
DefaultOrderedDict that has a single default value for missing keys |
Class Inheritance Diagram¶
tupa.model_util Module¶
Functions¶
glob(pathname, *[, recursive]) |
Return a list of paths matching a pathname pattern. |
jsonify(o) |
|
load_dict(filename) |
Load dictionary from Pickle file :param filename: file to read from |
load_enum(filename) |
|
load_json(filename) |
Load dictionary from JSON file :param filename: file to read from |
remove_backup(*filenames) |
|
remove_existing(*filenames) |
|
save_dict(filename, d) |
Save dictionary to Pickle file :param filename: file to write to :param d: dictionary to save |
save_json(filename, d) |
Save dictionary to JSON file :param filename: file to write to :param d: dictionary to save |
Classes¶
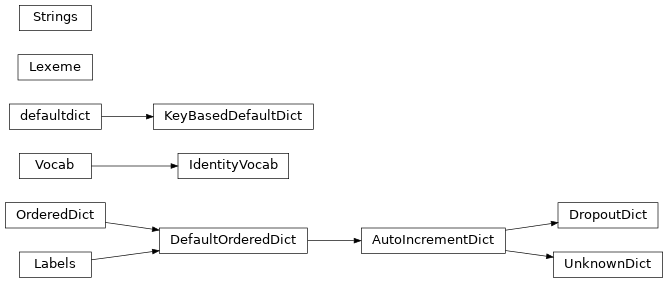
AutoIncrementDict([size, keys, d, unknown]) |
DefaultOrderedDict that returns an auto-incrementing index for new keys |
Counter(**kwds) |
Dict subclass for counting hashable items. |
DefaultOrderedDict([default_factory, size]) |
|
DropoutDict([d, dropout, size, keys, min_count]) |
UnknownDict that sometimes returns the unknown value even for existing keys |
IdentityVocab() |
|
KeyBasedDefaultDict |
|
Labels(size) |
|
Lexeme(index, text) |
|
OrderedDict |
Dictionary that remembers insertion order |
Strings(vocab) |
|
UnknownDict([d]) |
DefaultOrderedDict that has a single default value for missing keys |
Vocab(tuples) |
|
defaultdict |
defaultdict(default_factory[, …]) –> dict with default factory |
itemgetter |
itemgetter(item, …) –> itemgetter object |
Class Inheritance Diagram¶
tupa.oracle Module¶
Functions¶
is_implicit_node(node) |
|
is_remote_edge(edge) |
|
is_terminal_edge(edge) |
Classes¶
Actions([actions, size]) |
|
InvalidActionError(*args[, is_type]) |
|
Oracle(passage) |
Oracle to produce gold transition parses given UCCA passages To be used for creating training data for a transition-based UCCA parser :param passage gold passage to get the correct edges from |
Class Inheritance Diagram¶
